How RSS Brain Shows Related Articles
RSSprojectRSS Braindigital lifeIn the new version of RSS Brain, I added a new feature to show related articles from folders or feeds of your choice, instead of only showing related articles from all feeds.
I have mentioned this feature in the previous blog post. I also mentioned the algorithms in RSS Brain will be transparent. So in this article, I will talk about the details of this feature, how it can be used, the algorithm that backs it and how RSS Brain implements it.
What is the Feature
The feature is very straightforward: when you are reading an article from a feed, RSS Brain will show related articles at the end. It’s a very common feature. What makes RSS Brain different are two things:
- You can configure where the related articles come from.
- The implementation is transparent. That includes both the algorithm, which I will introduce in this article, and the code, which I will open source in the future.
How do you configure the related articles? By default, there will be no recommended articles. But there is a button to let you add a recommendation section at the end of an article:

Once you click the “Add More” button, it will show all your folders and feeds, with another “All Subscriptions” option. If you select “All Subscriptions”, this recommendation section will find related articles from all your subscriptions. If you select a folder or feed, it will find them from the folder or feed of your choice.
You can add multiple recommendation sections. After that, each recommendation section will be shown after the article. The screenshot below is an example that has a section that shows related articles from a folder called “local-form”, and another section that shows related articles from all the user’s subscriptions.
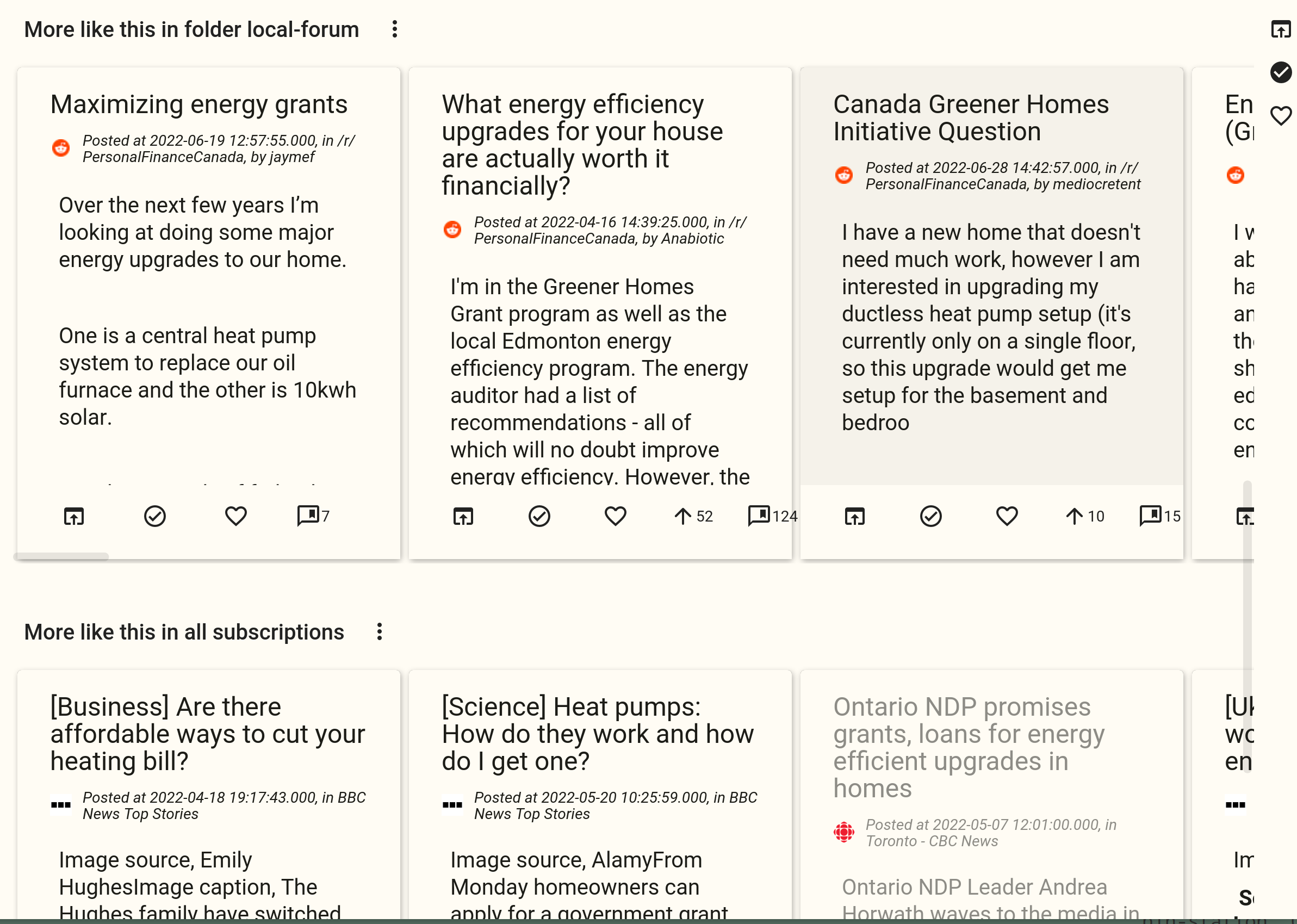
The recommendation configuration is attached to the feed that this article belongs to. So if you read another article from the same feed, it will show related articles from the same recommendation sections.
Why the Feature is Useful
The first way I use it is to find more discussions about this article. For example, you can configure it to show related articles from Hacker News, some Twitter account or from a sub Reddit. So that you know what other people think about this article, or about this topic.
Another way to use it is to check the coverage from different sources. For example, you can add a recommendation section that contains left wing media and another section that has right wing media, so that you can compare the coverage and get a whole picture.
Last but not least, the recommendation is useful in its traditional way: just show related articles about the same topic so that you can read more details about the same topic. I often just read folders that have high quality sources, and when I want to know more, I will add a recommendation section that has more sources and find articles to read from there.
How the Feature is Implemented
Update: see this blog for updated algorithm.
The algorithm to find recommended features is content based instead of user based. RSS Brain doesn’t collect any user’s information in order to make personalized recommendation. It just finds the related articles by how similar they are.
Each article can be represented by a term vector. The values in this vector are scores of the terms. For example, if article A has the content of “apple boy cat” and article B has the content of “apple boy dog”, the term vectors for each of the articles can be:
apple, boy, cat, dog
A: [0.5, 0.5, 1, 0]
B: [0.5, 0.5, 0, 1]
The score is computed by tf-idf, which is basically a score that considers both the frequency of the term in this article, and the frequency in all the articles: the more frequent it is in this article, the bigger the score since it can better represent the article. However the more frequent it is in all the articles, the score should be smaller since it’s not unique enough to represent the feature of this article. Once we have a term vector for each article, we can find the similarity by counting the distance between these vectors.
So we have the algorithm, but how does RSS Brain implement it in the code? We are using ElasticSearch under the hood. It’s widely used and open source. So for the APIs that RSS Brain is using, you can check the code for implementation details if you want. It has an API to find the term vector for an article, and we use the scores in the term vector to do a boosting query, which means do a search with different weights for each query term. For example, in the example above, if we want to find related articles for article A, we would find its term vector first, then convert the term vector into a boosting query that searches related articles by the query apple^0.5 boy^0.5 cat^1.
There are more details in this implementation, like adding filters on feed or folder in the query, limiting the term vector size and so on. The details can be found in the code once it’s open sourced. But the main idea doesn’t change.
With this simple and content based recommendation algorithm, instead of letting a black box AI decide what content is shown to you, I believe users can understand why an article is recommended, and judge whether the recommendation can benefit them or not.