Update on RSS Brain to Find Related Articles with Machine Learning
RSS BrainMachine LearningNeural NetworkEmbeddingsPythonIn the previous blog about RSS, How RSS Brain Shows Related Articles, I talked about how RSS Brain finds the related articles. I’ve updated the algorithm recently. This blog is about the details about the update. The basic idea is to replace tf-idf algorithm with text embeddings to represent the articles as vectors, and use ElasticSearch to store and query those vectors.
The Disadvantages of Previous Algorithm
First let’s do a quick revisit on the algorithm before the update: it’s using tf-idf algorithm. Which is basically an algorithm to represent each document as a vector by using the words’ frequency in it. It’s an algorithm that is easy to understand, and works well enough in practice to power lots of searching engines for a long time. However, it has a few shortcomings:
First, it doesn’t understand the meaning of the word. A word can mean different things based on context, order, combinations and so on. Different words can also have the same meaning. Word frequency alone doesn’t catch that.
Second, “word” needs to be defined. Which is a relatively easy task for languages like English, since it has a built-in word separator character (space). However, for languages like Chinese, there is no obvious way to separate the words. The performance of tf-idf algorithm largely depends on the performance of word separating algorithm, which itself is much more complex than tf-idf and often involves machine learning as well. Even for languages like English, in order to minimize the first disadvantage above, the words are usually broken down so that some similar words can be matched.
Last, which is an extension of the first disadvantage: it’s hard to do multi language matches. Word frequency alone doesn’t know that different words in different languages can mean the same thing. Of course you can translate the document to other languages and index the translated documents, but it doesn’t scale well when you need to support more and more languages. And translation algorithms are usually much more complex than tf-idf, and mostly use machine learning too.
Word and Document Embeddings
With the advancement of machine learning, a new method to represent words as vectors has been developed in the paper Efficient Estimation of Word Representations in Vector Space. The vector is called word embedding. Then based on the idea, Distributed Representations of Sentences and Documents explores representing paragraphs as vectors. Without going into the details, the basic idea is to get a layer from a neural network for an NLP task.
For example, if we have a neural network to predict the nth word given previous words, then we may have a neural network like this:
word[1] --> vector[1]
word[2] --> vector[2] --> layer2 --> ... -> classifier -> output
...
word[n-1] --> vector[n-1]
Words are mapped to vectors at the first layer, with something like
\[v = w * W + b\]Where \(v\) is the vector, \(w\) is the one-hot encoded word. And matrix \(W\) and \(b\) are the trained parameters. There are many other parameters in the later layers of the neural network but we don’t care. We only take \(W\) and \(b\) so that we can compute the vector for any word. With this method, the represented vectors can measure similarities between words by computing similarity of the vectors. Also surprisingly, quoted from the paper Efficient Estimation of Word Representations in Vector Space: “To find a word that is similar to small in the same sense as biggest is similar to big, we can simply compute vector \(X = vector(biggest) − vector(big) + vector(small)\).” What a beautiful result!
I was aware of this research not long after it came out. I believe some commercial search engines started to use it since then. But the ecosystem like models, tools, databases really picked up since GPT3 came out. So recently, I decided to use it in RSS Brain because how easy to do it nowadays.
Select a Model to Use
The first step is to select a model to use. I think OpenAI may have the best model that is available to public. You cannot access the real model but there are APIs you can call to use the model. But I don’t like it for 2 reasons: First, I don’t like OpenAI as a company: it presents itself as a non-profit organization first with the goal to make AI accessible to everyone, then stopped publishing models or even the algorithm details. Second, I don’t want vendor lock-in.
There is also Llama. But it’s not really a multilingual model. I see some attempts to train it on some other languages, but the results are not that good in my experience. The license of the model is not commercial friendly as well. And there is no easy to use API to get the embeddings.
At the end I found SentenceTransformers. There are lots of pretrained models in the project. In the end I selected the model paraphrase-multilingual-mpnet-base-v2 since it’s a multilingual model. But it’s called “sentence” transformers for a reason: there is a size limit on the length of document that you can feed in to the models. I ended up to just get the embeddings for the article title. I think it’s good enough for my use case.
Implementation Details for Model Server
The library SentenceTransformer is very easy to use. However it’s implemented in Python so it needs a way to communicate with RSS Brain server, which is written in Scala. Since this is a computation heavy task, the first thought is to have a buffer queue in between so that the Python program can process the articles in a speed it can handle. Kafka is a good choice for external task queue but I don’t think it’s worth the complexity to import another component into the system. So I created buffer queues at both ends to avoid creating too many requests while maintaining some parallelism. Here is what the whole architecture looks like:
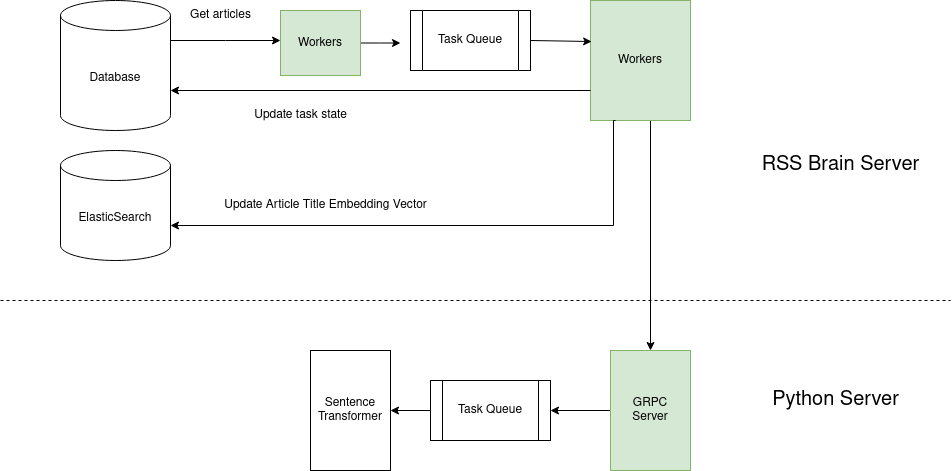
The green parts in the diagram mean the workers in them can work concurrently. On the Scala side, it follows the pattern I experimented in Compare Task Processing Approaches in Scala. On the Python side, it’s more tricky since Python’s async handling is far worse than Scala’s plain old Future, not to mention effect systems like Cats Effect. I may write another blog in the future about it.
The reason I go into great detail about this relatively simple problem is that it represents a category of problems: problems that need Python to do some async work because of the library supports. For example, in the future, Python server may have more features like fetching Youtube transcriptions. The architecture to integrate it into RSS Brain would be the same.
Database to Store and Query Embeddings
There are a few vector databases that can store vectors and query nearest vectors if given one. ElasticSearch added vector fields support at 7.0 and approximate nearest neighbor search (ANN) at 8.0. Since RSS Brain is already using ElasticSearch heavily for searching, I can just use it without adding another database to the dependencies. It also supports machine learning models so that you don’t need to insert the embedding vectors from the outside world, but I find it’s not as flexible.
Once the vectors are inserted into ElasticSearch, it’s just an API call to get the most similar documents. The details of vector insert and query are in the ElasticSearch KNN search document. One tricky part is that even though ElasticSearch supports combining ANN search with other features like term searches (tf-idf algorithm) by using a boost factor, it doesn’t work well unless you are willing to tune it. That’s because the embedding vector and term vector mean different things, and the similarity score is not really comparable. So I ended up enabling vector search only for finding related articles, instead of combining with term searches.
Result
It’s actually hard to have some metrics for the performance of finding related articles. I don’t believe metrics like click rate, since it doesn’t necessarily show the articles are related. I think the only way for me is to review the results manually and compute the score based on it. But I don’t think it has much value since supporting multiple languages alone would make it much better than the previous algorithm. But if you are using RSS Brain, you can see the results yourself and let me know what you think about the new algorithm!