Introduce K3s, CephFS and MetalLB to My High Available Cluster
KubernetesCephFSMetalLBk3sInfrastructuredevopsIn a previous blog Infrastructure Setup for High Availability, I talked about how I set up a cluster infrastructure for high availability applications. I have made a few changes since then. This blog is to talk about them in detail.
Updated Architecture Overview
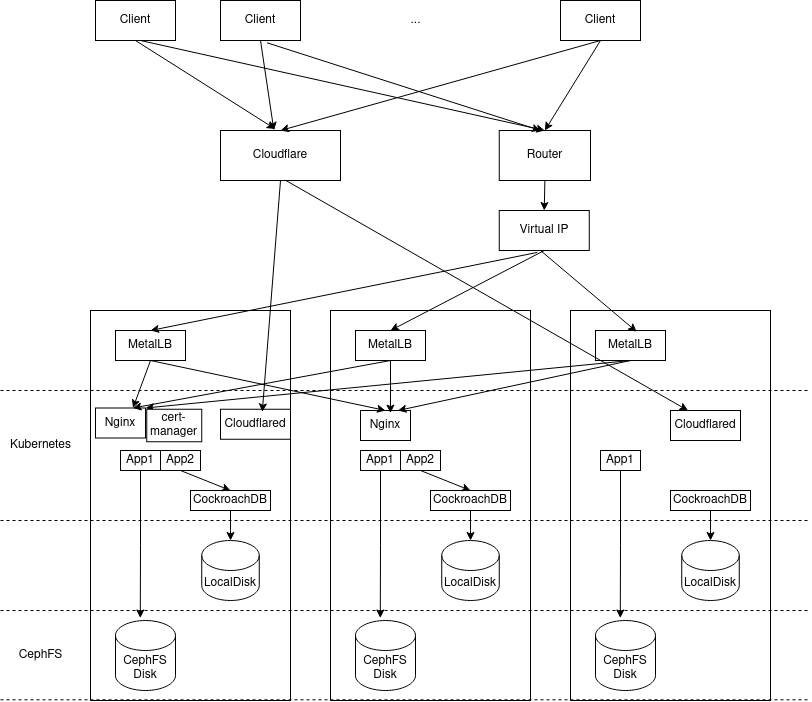
Comparing the diagram with the one in Infrastructure Setup for High Availability, the overall structure remains the same, with a few modifications:
- Not shown in the graph, but replaced official Kubernetes with K3s.
- Replaced GlusterFS with CephFS.
- Included cert-manager to get SSL certificates.
- Replaced Keepalived on each node with MetalLB.
Replace Kubernetes with K3s
I didn’t know K3s back when I set up my Kubernetes cluster for the first time. But since then I heard a lot of good things about it at various places. However, the complexity of migration and its installation method through a script from the Internet instead of an OS package made me think twice before adopting it. But after I watched the video Talk About K3s Internals from Darren Shepherd, I realized how simple k3s is compared to Kubernetes. I highly recommend everyone who is interested in K3s watch this video.
In short, K3s is a distribution of Kubernetes instead of a fork. It does these things with a few patches: combined the components of Kubernetes into one binary and process, and removed some components not needed in a bare-metal environment. By doing so, it makes its binary size and memory footprint smaller than Kubernetes, and makes it easier to deploy and manage. It only needs a binary k3s and a configuration file under /etc/rancher/k3s/config.yaml to start, and all of its content is under /var/lib/rancher/k3s. The official install script adds a little bit more than just the binary file: it has a few scripts to kill and uninstall k3s. It also includes a systemd file to start/stop k3s through systemd. So even though it’s not packaged into a standard OS package, I think the complexity is manageable so I started to experiment with it.
It’s very easy to configure K3s since all it needs is a configuration file on each machine. I created a virtual machine cluster with Vagrant in the project k3s-vm-cluster to experiment with it. Feel free to play with it to get a feel of it before going all in. The setup is based on the official guide for High Availability Embedded etcd. It’s the easiest way to set up a highly available K3s cluster.
No load balancer setup is needed if no external Kubernetes API server HA is needed. That means, you can access to Kubernetes API server within the cluster if any of the machine fails. But if you still want to access it outside of the cluster during a failure, check this doc. Alternatively, I think load balancer like MetalLB can also do it, but I don’t need it so I didn’t experiment with it.
Distributed Storage System: GlusterFS to CephFS
The biggest motivation drives this migration is the deprecation of GlusterFS. I’m using distributed file system for a few use cases:
- Configuration files: this can be migrated to Kubernetes ConfigMaps.
- Logs: this can be migrated to a centralized log management system like ElasticSearch. But some of them like Loki in turn depends on another distributed storage.
- Data files: this is most complex one. Some of the services support saving files into S3 compatible systems. But some of them don’t. (I cannot control the services since I only self host them instead of developed them). One option is to not having HA and just bind those services into a specific host and use local storage.
- Docker registry: this belongs to the point “Data files” above, but this is very important so I separate it into another point. I’m using Sonatype Nexus as the docker registry. It supports to put packages into S3 but still pretty tricky to get rid of all the local files. This is a service that absolutely needs HA if I want to have a HA cluster. Or I can change to another Docker registry implementation, but I feel pretty comfortable using it so I don’t want to change it.
So it basically comes down to these 2 options:
- Use a S3 compatible storage like MinIO but do a lot of work to configure services to store files into that, and make services cannot do that not HA anymore.
- Go ahead and uses a real distributed file system like CephFs or Longhorn.
Update: I also explored LINBIT which I forgot to write it here. It got more and more complex when I went into the rabbit hole. But its architecture looks very interesting to me. So I may explore it more in the future for other use cases.
Option 1 sounds appealing to me at first since I really don’t want to deal with the complexity of setting up CephFS. But as I go into the rabbit hole, I found configuring the services to use S3 may be a more complex process and less portable than just setup CephFS. So at the end I decide to go option 2.
I’ve heard of CephFS long time ago but decided to use GlusterFS at previous setups because of the level of user friendly. So CephFS seems like a natural choice after GlusterFS is deprecated. Especially when I found other than the distributed block device, it also supports file system and S3 compatible storage system. It’s also easier to install than before because of Rook. Longhorn is another choice I looked a little bit but because of wider adoption of CephFS and more features of it, I decide to use CephFS at the end.
The way I use it is mainly Ceph Filesystem, so it’s easier to share volumes between pods. Again, the project k3s-vm-cluster has an example about it. Try to play it if you are interested in it. Along the way I actually contributed to Rook project by improving doc (#13045) and its error message (#13046).
Network Gateway
In the previous article, I talked about using Cloudflare tunnel, or NodePort and Keepalived to expose services to the Internet. But there are some other things a network gateway can do other than just expose the service: it can also do things like terminate SSL encryption and so on. Cloudflare tunnel supports terminating SSL at their end so I don’t need to worry about that. But for some services, I don’t want Cloudflare to see the traffic, so I need to terminate SSL and expose service by myself.
As I said, expose service part was done by NodePort and Keepalived, which is not very elegant but works. For the terminate SSL part, I was using Nginx as reverse proxy. But updating SSL certificates is a little bit more complex. I don’t want to talk it in details here because the setup is pretty complex and explaining it will be very lengthy. The point is, with this migration, I want to revisit this part to make it simpler and more elegant.
Kubernetes has a concept of Ingress, and newer but less mature, Gateway. What they are doing is essentially reverse proxy like Nginx. In fact, Nginx Ingress is a thing. The advantage is that you don’t need to configure all the services in a single place like Nginx’s configuration files. You can create Kubernetes resources for each of the service. So that the deployment and configuration of each service is totally self contained. This is a very good feature, especially for a company: when I first started to use Kubernetes at 2015 in a previous company, I felt the pain of not having it. But the feature of Ingress is pretty limited. For example, it can only bind to 443. It cannot modify the http content, and so on. So that I may still need a layer of Nginx for my use cases. The design of gateway is too complex and the features don’t really meet all my requirements as well.
There are some players like Traefik(shipped with K3s by default) and Istio which overcome the limitations by having their own custom resources. But Traefik cannot get new certificates from Let’s Encrypt with a HA setup. Istio is just too complex and include features like service mesh that I don’t need. I can see how service mesh can be useful in big companies, but I prefer not to have another layer on my own service. At the end, I don’t think the complexity worth it.
But while I exploring Traefik and Istio, I found cert-manager, which can be deployed into Kubernetes. It can get certificates from Let’s Encrypt and put them into Kubernetes secrets, which then can be mount into each pods. It supports Cloudflare DNS API for ACME DNS challenge, so I don’t need to export a http service for Let’s Encrypt to verify the ownership of the domain name. With all of this features, I decided to use it and mount the certificates into Nginx pods. It resolves the problem of update certificates from Let’s Encrypt.
For the other problem of exposing the services to Internet in a HA way, I want to use a more Kubernetes native way instead of setup Keepalived outside of the Kubernetes cluster. Kubernetes supports external load balancers. But most of the load balancers it supports are from cloud. Then I found MetalLB, which supports creating a HA load balancer without special hardware in a bare metal cluster. I use it with layer 2 mode, which creates a virtual IP like keepalived and can failover to another node.
Deploy Services with Code
What I didn’t talk about in the previous blog is that I define the deployment of my services as code instead of YAML files. It gives lots of advantages: first, you can create models for your own deployment pattern so that you can avoid lots of redundant code. Traditionally it’s hard to define the deployment as code. There are lots of frameworks to do it but none of them is easy to use. But with Kubernetes, all you need is generating a resource object for Kubernetes to use at the end. You can construct it in any way with your favorite language, and either output a YAML or call Kubernetes API directly. It’s using a high level language instead of writing machine code directly. It’s much more elegant and the maintenance is much easier. Be aware: use a real language instead of some template language. Why limit your power to do things?
This approach works so well especially during this migration. For example, I abstracted all the storage layer for my services, so that when I migrated from GlusterFS to CephFS, I just need to change the storage class to define the CephFS volume, and the code for services don’t need to change much.
Hope you enjoy my experience of setting up a HA cluster. Happy hacking and have fun with your own cluster!